Joshua Tree Parable
 Once upon a time, a boy from a farm in Iowa got an exciting opportunity to move to the west coast. While many new experiences awaited him there, he found himself imprisoned in a cage made of cars. After many years, he had never managed to escape the prison of cars to do simple things like learning to surf or exploring the natural beauty nearby. Later he realized that the prison was in his mind and driving to Joshua Tree is really not that big a deal. And it’s totally worth it.
Once upon a time, a boy from a farm in Iowa got an exciting opportunity to move to the west coast. While many new experiences awaited him there, he found himself imprisoned in a cage made of cars. After many years, he had never managed to escape the prison of cars to do simple things like learning to surf or exploring the natural beauty nearby. Later he realized that the prison was in his mind and driving to Joshua Tree is really not that big a deal. And it’s totally worth it.
Filed under: Posted by Greg Ver Steeg | 1 Comment
In academic work, page restrictions in publications often mean that there is not enough space to explore interesting but tangential relationships between ideas or to give more than bare-bones proofs of mathematical ideas. I am hoping to remedy this, at least initially, with a webcast series of three talks at ISI. I’ll post the links here. These are on the technical side. The eHarmony talk is a little more general of an introduction.
Learning Succinct and Informative Representations: Background and Big Picture
This talk contains some background about information theory and a few famous ideas on how to use it for learning.
- InfoMax This famous principle says something very intuitive. A good representation should have maximal mutual information with the data. I briefly discuss why this is wrong. (The short version: maximizing mutual information is like memorizing, and memorizing is not the way to build powerful representations with layers of abstraction.)
- Information decomposition This is one of my favorite topics. I talk about some classic Venn diagrams in information theory, Partial Information Decomposition from Beer/Williams, and a classic result from Watanabe about how multivariate mutual information can be decomposed. This decomposition motivates an interpretation of CorEx as hierarchical information decomposition.
- Information bottleneck The principle behind the bottleneck is to lossily compress data in a way that minimizes some distortion measure. In this case, they focus on supervised learning and take maximizing relevance about labels as a distortion measure. CorEx can be viewed as a compression with an unsupervised distortion measure where we try to retain the most redundant information in the data.
- Independent component analysis This one was at the end and got short shrift. ICA also has a compression interpretation. CorEx finds successively less dependent components at each layer (same with the information sieve, which we’ve used for discrete ICA).
- Generative models A popular way to do learning is to assume some generative model and then fit parameters to maximize the likelihood of the data. This requires a lot of up front assumptions. The perspective we take is the opposite: you say what type of computational structure you can support (i.e., calculating some probabilistic functions in parallel), and then optimize an informational objective with those resources. This doesn’t require model assumptions and, depending on the objective, has an operational meaning even if your model is mis-specified.
Part 2 will have a quick recap, filling in some things I missed in part 1. Then we’ll get into some in-depth derivations and implementation details about using CorEx to learn representations. Part 3 will get into the new directions (information sieve, temporal representations, …).
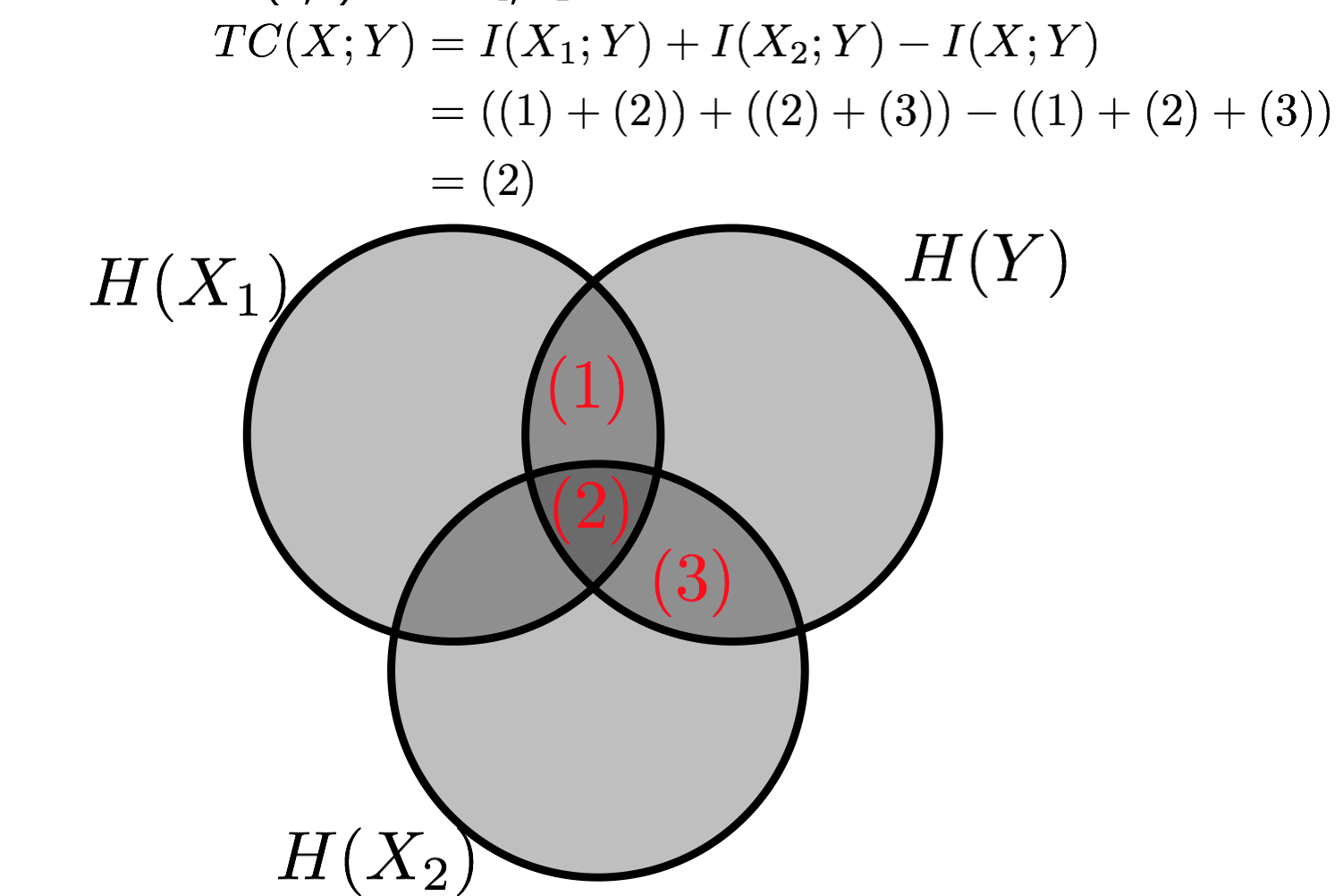
This shows the Venn diagram for a special case where Y explains correlations between two variables, X1, X2. In that case, the objective reduces to the triple information and is maximized if X1 and X2 are conditionally independent given Y.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
I just put up a new paper with the (hopefully) intriguing title “The Information Sieve“. The motivation is that when we humans look at the world, we tend to identify a new pattern or learn a new trick, and then we move on to the next thing. There are two amazing things about this:
1. We don’t learn everything at once.
2. We don’t re-learn the same thing over and over again (usually).
These may seem inconsequential, but it turns out to be very difficult to get machines to learn in this way.
The information sieve introduces a new way of learning things piece by piece. There is some amount of information in whatever data we are looking at, but we don’t know how much (and it’s usually impossible to exactly find out because of limited data/computation). We pass the data through the first layer of the sieve to extract the “most informative” pattern in the data, the data is transformed and the remaining information trickles down to the next layer of the sieve. This “remainder information” contains all the information from the original data except for what was already learned. This allows incremental learning that is guaranteed to improve at each step, and to never duplicate effort by re-learning what is already known.
The bonus eigen-faces below are not in the paper, but they show what the sieve extracts at various layers (when looking at a classic dataset called the Olivetti faces). Any face can “activate” any of these 10 learned factors. The blue/red shows how different pixels in the image contribute to whether that factor is activated. One seems to correspond to faces looking left or right (bottom, second from right). Others seem to focus on different parts of the face reflecting facial expressions. Anyway, there is more to be done to make this method practical on larger datasets, but this seems to be a promising first step. (The paper also shows how this method applies to lossy and lossless compression and independent component analysis, in case that is your bailiwick.)

Some eigen-faces learned with the information sieve.
Filed under: Posted by Greg Ver Steeg | 2 Comments
Deep learning for insights
I admit that this is a bit of a melodramatic title. I was actually a little surprised that, before I used it, the phrase “deep learning for insights” did not exist in google. I gave a talk at eHarmony with this title, for the LA machine learning group. The video is posted here. The original announcement also has links to the slides.
The point of the title was that deep learning as we know it is amazing as a black box that does certain types of prediction (e.g. object recognition in images), but if you feed in a messy dataset and then look inside the box it’s difficult to gain any understanding of the data from that. Generally, this is a consequence of the fact that the optimization is “global”: every hidden unit contributes collectively towards doing a better job at predicting labels. There is no reason to expect an individual hidden unit to have an interesting meaning. In contrast, for “maximally informative representations” each layer and hidden unit has a quantifiable contribution towards the information it contains about the data.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
I’ve been working on a series of posts about an exciting line of work I’m pursuing. The groundwork is in this paper. The basic idea is that any thing we learn from inputs should be considered a representation. What would happen if we searched over the space of all representations for one that is most informative about the inputs? It turns out we can do that efficiently and it leads to a nice hierarchical structure that does a great job at learning from diverse data from gene expression, finance, language, human behavior, and more.
I’m in the process of preparing a sequence of in-depth posts on this new direction, how it fits into the deep learning landscape, what the practical implications are, and the implications for understanding intelligence. In the meantime, here is another cute picture (produced with 1-click from 100 samples of hand-written digits with no other prior information and no hyper-parameters).
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Correlation Explanation Preview
A “real” blog update will be some time coming. In the meantime, there are some pretty pictures from preliminary results if you click around here.
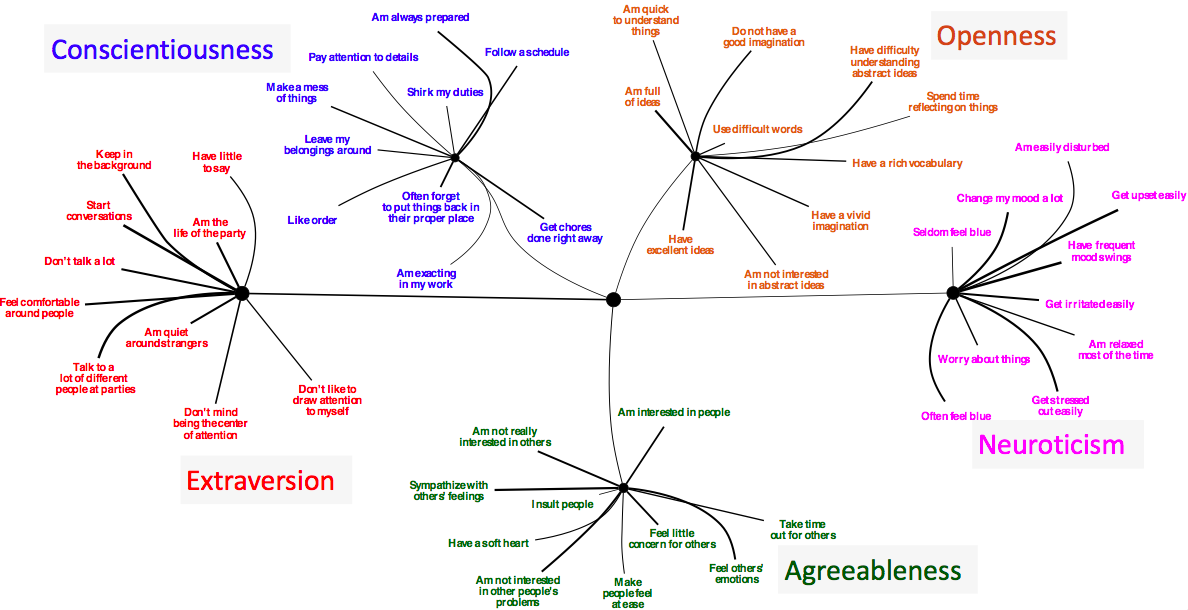
The picture below is a cool result where our method took results from survey questions (like “Are you the life of the party?”) and automatically discovered that there should be five traits that explain the correlations between how people answered questions. It turns out that the result perfectly matched the “big 5” personality traits. We also got cool (preliminary) results using data from DNA, gene expression, and human language.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Demystifying Information-Theoretic Clustering
Quick summary: Finding clusters in data is a fundamental problem in machine learning. You’d like to be able to do so without making any assumptions about your data. Information theory provides a good way to do this, but the first few attempts to do so have been fundamentally flawed. We fix the flaws and show that it leads to much better clusters. Almost every clustering paper shows a picture like the one on the left below. What they don’t show is that they have carefully picked the size of the circles so that their clustering method works. Our method (CVR) works for arbitrarily sized clusters.
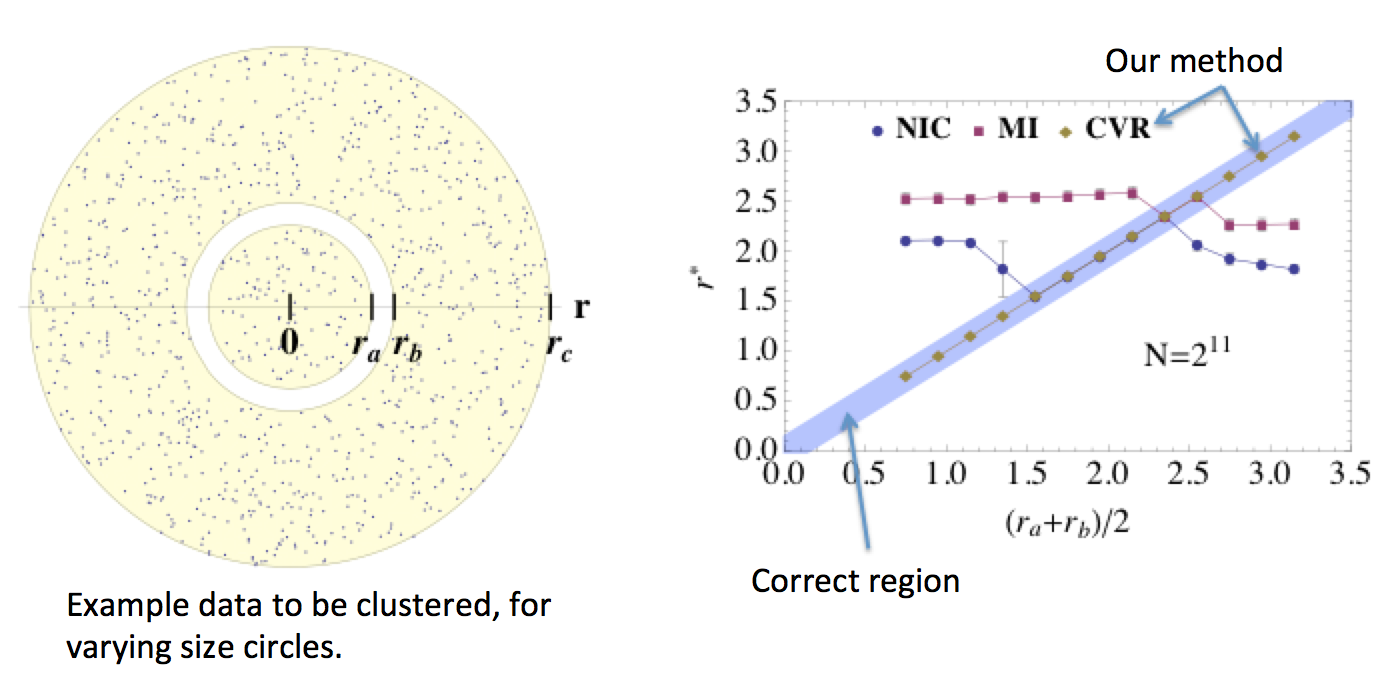
Using information theory to find clusters is a nice idea, but previous attempts (NIC,MI) were totally wrong, and would only work for carefully hand-picked examples. Our method (CVR) works for arbitrarily sized clusters.
MAX 2-SAT with up to 108 qubits
Quick summary: If you read Shtetl-optimized, you’re aware of the ongoing drama surrounding the D-Wave quantum chip. There was a widely publicized paper showing some speed-ups in solving certain problems with the D-Wave chip. Those speed-ups evaporated when compared to state-of-the-art classical solvers. In the debate at Shtetl, Scott says:
In the comments, many people tried repeatedly to change the subject from [whether a speed-up has been demonstrated] to various subsidiary questions. For example: isn’t it possible that D-Wave’s current device will be found to provide a speedup on some other distribution of instances, besides the one that was tested?
That is basically what we were trying to explore in our paper. We have some knobs to tune the distribution of problems to see which ones are easier or harder. Can we reveal a difference in hardness for the classical and quantum solvers? The answer is a tentative yes, but there is more to be done here.
Other things
I went to the WIN workshop again this year. I talked about some recent ideas about detecting contagion. Although “latent homophily” has gotten a lot of discussion as a methodological problem, we showed that it can be overcome, while “external dynamics” provide a more fundamental (and frequently ignored) obstacle to detecting contagion.
Shuyang Gao gave an outstanding talk about “stylistic accommodation”. Have you ever noticed that when one person yawns, it makes other people yawn too? The question in this line of research is whether one person’s use of a particular style of speech affects the style of speech of people responding. Previous research had purported to find strong effects of this kind, but Shuyang showed that almost all of these correlations are due to confounding factors.
Finally, I’ll be in India in December, and I’m planning to visit the Tata Institute of Fundamental Research (in Mumbai) while I’m there.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Non-Parametric Entropy Estimation Toolbox (NPEET)
I finally got around to packaging together bits of Python code that are useful for estimating information-theoretic quantities for both continuous and discrete variables. This is in preparation for a tutorial I’m giving next week at ICWSM.
The documentation[pdf link] contains detailed descriptions along with discussion of the technical challenges.
Filed under: Uncategorized | Leave a Comment
Tags: Posted by Greg Ver Steeg
Correlation doesn’t imply causation (but some correlations can imply at least some causation)
If you’ve been reading science news, you’ve seen over the years that obesity, happiness, loneliness, and divorce are all contagious. Just a few weeks ago, I read that grades are also contagious. Certainly, it’s not surprising to find out that friends’ behaviors are correlated on all these fronts, but is that enough to say for sure that your friends cause you to become more obese/happy/lonely etc.?
Generally, the answer is no. Shalizi explains on his blog and in a paper with Andrew Thomas why this is the case. The basic idea is expressed in the picture below. It could be that Alice influences Bob directly, but it could also be (for example) that Alice has joined a Pie-Eating club and Bob has joined the same club. The Pie-Eating club explains why they both have a tendency to become obese and it explains how they became friends. The club, in this case, is a hidden variable that gives an alternate explanation for correlations in obesity.
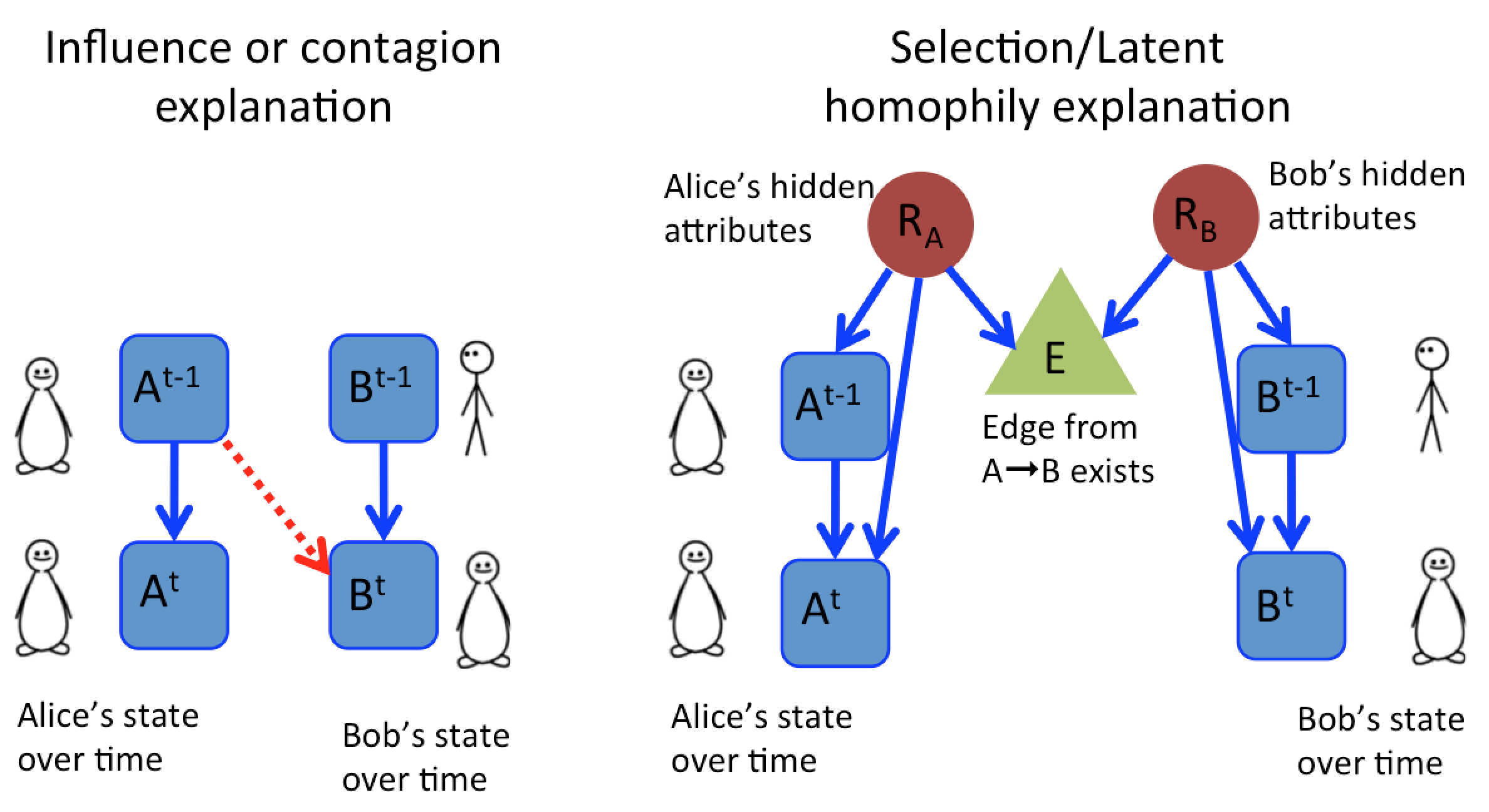
The problem is that it is easy to come up with more and more elaborate hidden variables that might explain correlations in, e.g., obesity, and we could never hope to account for them all. Is hope lost? Not quite.
It turns out that a similar problem arises in quantum physics. Einstein saw the “spooky action at a distance” implied by quantum physics and declared that it could not be: ultimately, there must be some hitherto unmeasured hidden variables that explain the correlations between distantly separated particles. Amazingly, Einstein was wrong and John Bell demonstrated a simple test that would be satisfied by any hidden variable theory but is violated by quantum physics. What we do is extend this reasoning for correlations in social networks. We don’t want to account for every possible source of correlations (like Pie-Eating Club, yum), we want a test that tells us that no hidden variables explain the correlations and therefore there must be some influence between friends.

Everything else is just mathematical details. We show how to construct these types of tests in a general way. In the end, we were able to show that hidden variable theories do not explain the correlations in obesity and, therefore, some other causal effect is needed to explain what is going on. Of course, my language here is purposely cagey, as all causality researchers are:

You will have to see the paper for all the caveats, but I can make the bold statement that according to the best causal tests, obesity is contagious, probably.
I’m presenting this work at AISTATS, here is the paper which builds on work I previously discussed.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
