Learning Succinct and Informative Representations: Part 1 of 3
In academic work, page restrictions in publications often mean that there is not enough space to explore interesting but tangential relationships between ideas or to give more than bare-bones proofs of mathematical ideas. I am hoping to remedy this, at least initially, with a webcast series of three talks at ISI. I’ll post the links here. These are on the technical side. The eHarmony talk is a little more general of an introduction.
Learning Succinct and Informative Representations: Background and Big Picture
This talk contains some background about information theory and a few famous ideas on how to use it for learning.
- InfoMax This famous principle says something very intuitive. A good representation should have maximal mutual information with the data. I briefly discuss why this is wrong. (The short version: maximizing mutual information is like memorizing, and memorizing is not the way to build powerful representations with layers of abstraction.)
- Information decomposition This is one of my favorite topics. I talk about some classic Venn diagrams in information theory, Partial Information Decomposition from Beer/Williams, and a classic result from Watanabe about how multivariate mutual information can be decomposed. This decomposition motivates an interpretation of CorEx as hierarchical information decomposition.
- Information bottleneck The principle behind the bottleneck is to lossily compress data in a way that minimizes some distortion measure. In this case, they focus on supervised learning and take maximizing relevance about labels as a distortion measure. CorEx can be viewed as a compression with an unsupervised distortion measure where we try to retain the most redundant information in the data.
- Independent component analysis This one was at the end and got short shrift. ICA also has a compression interpretation. CorEx finds successively less dependent components at each layer (same with the information sieve, which we’ve used for discrete ICA).
- Generative models A popular way to do learning is to assume some generative model and then fit parameters to maximize the likelihood of the data. This requires a lot of up front assumptions. The perspective we take is the opposite: you say what type of computational structure you can support (i.e., calculating some probabilistic functions in parallel), and then optimize an informational objective with those resources. This doesn’t require model assumptions and, depending on the objective, has an operational meaning even if your model is mis-specified.
Part 2 will have a quick recap, filling in some things I missed in part 1. Then we’ll get into some in-depth derivations and implementation details about using CorEx to learn representations. Part 3 will get into the new directions (information sieve, temporal representations, …).
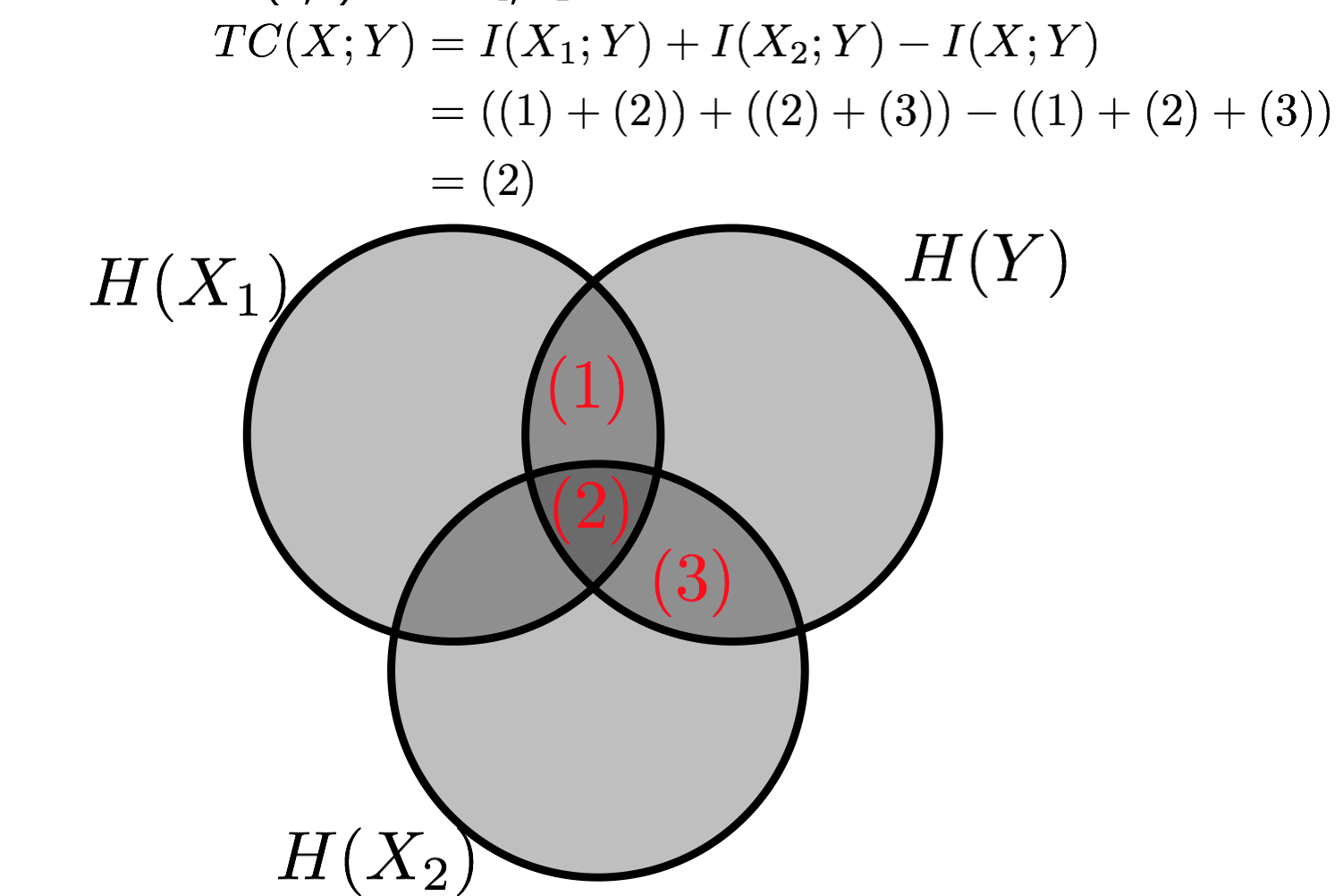
This shows the Venn diagram for a special case where Y explains correlations between two variables, X1, X2. In that case, the objective reduces to the triple information and is maximized if X1 and X2 are conditionally independent given Y.
Filed under: Posted by Greg Ver Steeg | Leave a Comment

No Responses Yet to “Learning Succinct and Informative Representations: Part 1 of 3”