My Facebook Network
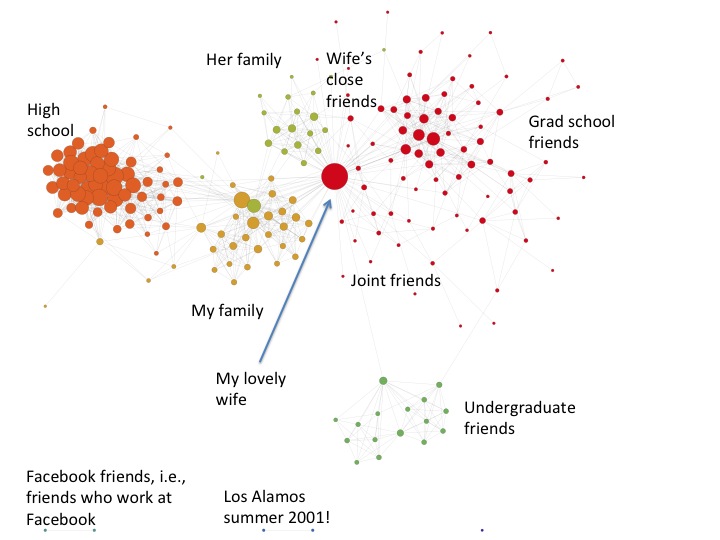
Thanks to the magic of Mathematica 9, you can now make pretty pictures of your social networks with a single command. I was impressed by how well it automatically captured the true structure of my network, which I labeled and included below. I’m not sure what you can conclude about me as a person, except that I’m happy to route all socializing through my more extroverted wife. It’s probably also pretty clear which parts of my life are geographically separated.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Black holes
In grad school I collaborated with Chris Adami on some papers about black holes. We suggested that some of the mysteries surrounding black holes may evaporate if you correctly include the effects of stimulated emission. Chris is presenting some of these results now at the APS meeting, and on his new blog. (paper)
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Can we measure the effect of one person’s words on another person? I want to describe the main idea behind my recent paper, Information-Theoretic Measures of Influence Based on Content Dynamics, which I’m presenting at WSDM 2013.
Ostensibly, information theory is a dry, academic subject about how to send 0’s and 1’s through a noisy channel (like browsing the web using your cellular signal). The goal is to encode the information so that all the bits can be recovered after they are sent through a noisy channel. Shannon’s theory tells us that the amount of information we can send through the noisy channel is related to a quantity called “mutual information”.
![]()
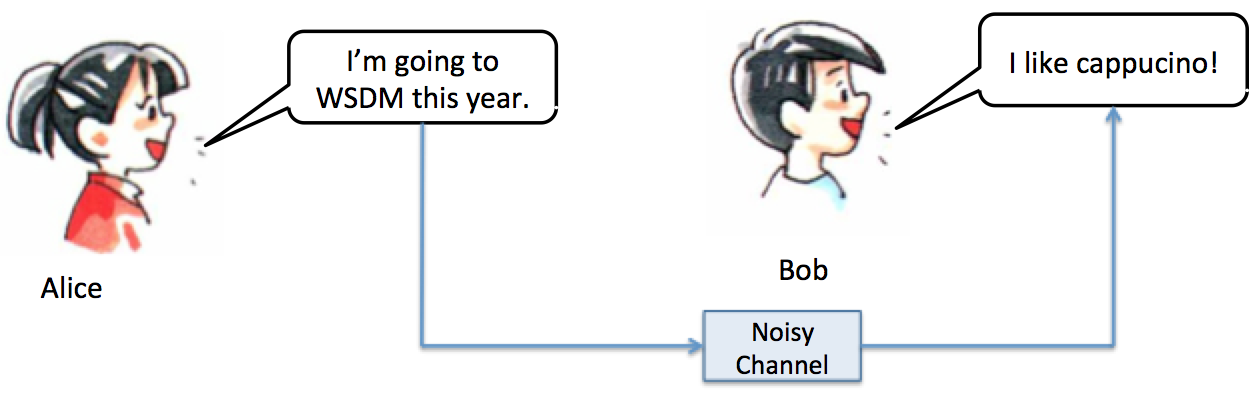
What does this have to do with influence, human speech, or social media? This abstract framework is remarkably flexible. What if the input is some statement made by Alice. Then the “noisy channel” consists of (e.g.) sound waves, the ear drum, and the brain of Bob. Now Bob “outputs” some other statement. In the example below, Bob has said something very relevant to Alice’s statement: WSDM is in Rome, so Alice should definitely have some coffee while she’s there. Bob’s statement gives us some information about what Alice’s original statement was.
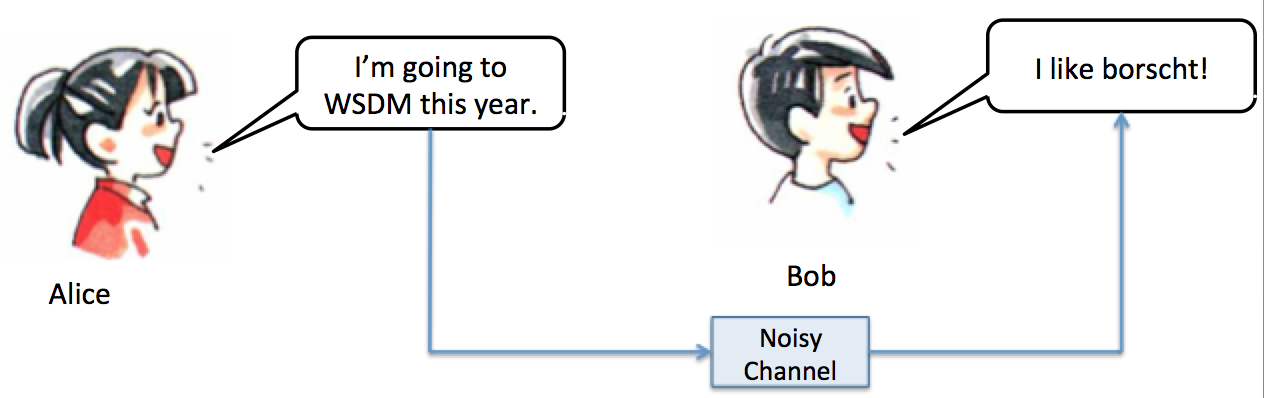
If, on the other hand, Bob had proclaimed his love of borscht, it’s not obvious that this has anything to do with Alice’s statement. Clearly, Bob lives in his own universe, day-dreaming of borscht. His statements carry no information about Alice’s statements.
How do we measure this notion of whether Bob’s statements carry information about Alice’s? We just use the standard information-theoretic notion of mutual information.
![]()
Unfortunately, this quantity depends on us being able to determine the probability of every pair of statements we might see Alice and Bob utter. Unfortunately, at best we might have observed a few hundred statements from Alice and Bob (on Twitter, for example). We have to do two things:
1. Simplify our representation of these statements (or “reduce the dimensionality of the signal”). That means Alice’s statement is reduced to some keywords that it might be about. (Some details: we use a popular technique called topic modeling to achieve this.)
2. Estimate mutual information using these simplified signals. (Some details: we actually use a more nuanced measure called conditional mutual information, or transfer entropy. We use non-parametric entropy estimators that avoid the step of estimating high dimensional probability distributions.)
Surprisingly, we were able to carry this procedure out for some users on Twitter and detect signals in human speech! One way to understand this result is to say that we could find user pairs where Bob’s statements could be predicted better if we knew Alice’s recent statements. It will come as no surprise that human speech is nuanced and complex, so we were only able to detect very predictable relationships. For instance, one triad of strongly connected users were three tri-lingual sisters. If one of the sisters tweeted to the others in a specific language, the others would always respond in the same language. Other strong relationships included news dissemination and web site promotion. Can we do better and detect more complex forms of influence? Sure, we need either more data or better representation of content or better entropy estimators. We’re working on all three!
Filed under: Posted by Greg Ver Steeg | Leave a Comment
New preprint: http://arxiv.org/abs/1208.4475. The title is changing to: “Information-Theoretic Measures of Influence Based on Content Dynamics”. I’ll give a detailed, readable summary in a week or two. I’ll be presenting about this at WIN workshop, so please come!
For now, imagine the following problem. There are hundreds of people in a large room talking to each other. You can hear what everybody is saying, but you don’t know who’s talking to whom. How could you figure it out, based on the what they are saying? If one person says something, and another responds, we can usually tell that it fits with the original statement somehow. We quantify this intuition using information theory. If we interpret both people’s utterances as arbitrary signals, then we can use very general information theoretic tools to tell us if one signal is predictable from the other. I.e., one person’s statements are more predictable if we know what the other person is saying.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
Misspellings for google
Sadly, I was not born with a sensical one-word last name, leading to various problems throughout life. For googling purposes, the all-too-common misspellings:
GV Steeg
Greg Steeg
Greg VerSteeg
Filed under: Posted by Greg Ver Steeg | Leave a Comment
A busy month
Next month on April 9 I’ll give a talk for UC Irvine’s AI/ML seminar. The next week I’ll fly to Lyon, France for WWW (the World Wide Web conference). I’ll be giving a talk at a workshop before WWW called “Making sense of micro posts”. Then I’ll present my and Aram Galstyan‘s paper “Information Transfer in Social Media” at WWW.
In the meantime, I hope to finish a paper for UAI while continuing to teach “Physics and Computation”. After all that, perhaps a visit this summer to a research group in Singapore? More details on that later.
Filed under: Posted by Greg Ver Steeg | Leave a Comment
CS 599 and me drinking Kool-aid
I’m teaching a graduate course this term at USC with Aram Galstyan called “Physics and Computation”. Basically, it shows how we can use statistical physics to understand problems in computer science. Hopefully I’ll post some details about the class later. For now, here’s the main text we’re using: Information, computation, and physics.
In a classic two-birds-one-stone maneuver, we’re thinking about some projects that the students could do that relate to the big question: what can we do with a D-Wave chip? Both 2-SAT instances and spin glass (or LDPC) codes are exactly representable as Ising models that can be solved on the chip. Conveniently, these are both problems we’ve been studying in detail in the course: their phase transitions, average complexity, best classical algorithms, etc. Here’s a toast to a hopefully synergistic term.

Filed under: Posted by Greg Ver Steeg | Leave a Comment
It’s official
Lockheed bought a D-Wave quantum chip for USC which is now being installed at ISI. Press release. I got to see the large refrigerated, magnetically shielded box yesterday. Now, what shall we do with it?
(Edit: sorry, link fixed.)
Filed under: Uncategorized | Leave a Comment
Decoding the Twitter brain
I finally have a working paper up called Information transfer in social media, related to the talk I gave at WIN. Read on for a quick explanation.
Neurons in the brain give sporadic electrical spikes. How does the pattern of neuronal spikes correspond to a thought? Or, how are our thoughts coded as electrical spikes? Researchers in neuroscience turned to information theory as the most general mathematical framework we have for answering this question. Basically, this allows them to quantify how much information is contained in a signal of spikes, and to correlate that information with different external stimuli (e.g. a picture of a cat).
We imagine that each person in a social network is a neuron and each tweet or post corresponds to a spike of activity. Can we use information theory to decode what’s going on? If you follow someone on a social network, do they really affect your actions? Intuitively, we know that the answer is sometimes “no”; many of our Facebook “friends” are nothing of the sort.
We want to uncover the “real” network of connections that make people tick. We can do this in a statistical way with enough data. Roughly, we measure how much our uncertainty about what you will do next is reduced if we know what the person you are following has done.
The results are surprising. We are able to deduce a lot about what’s going on just from the timing of tweets. One person’s weak influence on a million followers may amount to less than another person’s strong influence on a hundred thousand followers. Another interesting result is that the most predictable activity on Twitter comes from spammers. I’m including some of the high information transfer clusters below. Some are in the paper and some are apparenthorizons.com exclusives.
(Flippant) commentary is in picture order. You can check out any of these accounts by going to twitter.com/username, though the spammier accounts have been banned.
Soccer cluster: delwardhk really loves his soccer. I can’t be sure whether he personally retweets all the regional soccer accounts, or if it’s automated.
Drug cluster: The international viagra drug cartel has finally been revealed through science.
Bieber cluster (only a piece): I don’t think this is spam, these people are really obsessed with Justin Bieber.
Webcam cluster: I didn’t explore this in detail. Apparently these young ladies will chat with you over their webcams. That sounds sweet.
Spam-of-all-trades: What’s your game friend? Are you into marketing, travel, escorts, or pantyhose? How can you justify cross-posting to all these accounts?
Boogie cluster: These are night club promoters. Boogie Fonzarelli is the greatest name ever constructed. My firstborn will have to be named Boogie Fonzarelli Ver Steeg.
Filed under: Posted by Greg Ver Steeg | 2 Comments
Quick UAI update
UAI 2011 has ended, and it went really well. I was happy with my talk and surprised at how many people at UAI were interested in quantum stuff!
There were many interesting presentations but I want to mention one in particular because it’s on my mind and it has a nice connection to my talk.
My talk was about detecting the existence of hidden variables. This is only possible if the effect of the hidden variable is constrained. One route, which I took, is to say that the hidden variable may be arbitrarily complex but it doesn’t change in time, nor do actors’ dependence on it change in time. But there was an interesting paper which took a different route:
“Detecting low-complexity unobserved causes” by Dominik Janzing, Eleni Sgouritsa, Oliver Stegle, Jonas Peters, Bernhard Schölkopf
In this case, the effect of the hidden variable is constrained by assuming a low complexity hidden variable. This constrains the possible effects on observed variables and therefore gives you a signature to deduce their existence. I will be reading this paper closely!
Filed under: Posted by Greg Ver Steeg | Leave a Comment
