The “Grue” problem (and deep learning)
The Grue language doesn’t have words for “blue” or “green”. Instead Grue speakers have the following concepts:
grue: green during the day and blue at night
bleen: blue during the day and green at night

(This example is adapted from the original grue thought experiment.) To us, these concepts seem needlessly complicated. However, to a Grue speaker, it is our language that is unnecessarily complicated. For him, green has the cumbersome definition of “grue during the day and bleen at night”.

How can we wipe the smug smile off this Grue speaker’s face, and convince him of the obvious superiority of our own concepts of blue and green? What we do is sneak into his house at night and blindfold and drug the Grue speaker. We take him to a cave deep underground and leave him there for a few days. When he wakes up, he has no idea whether it is day or night. We remove his blindfold and present him with a simple choice: press the grue button and we let him go, but press the bleen button… Now he’s forced to admit the shortcomings of “grue” as a concept. By withholding irrelevant extra information (the time of day), grue does not provide any information about visual appearance. Obviously, if we told him to press the green button, he’d be much better off.
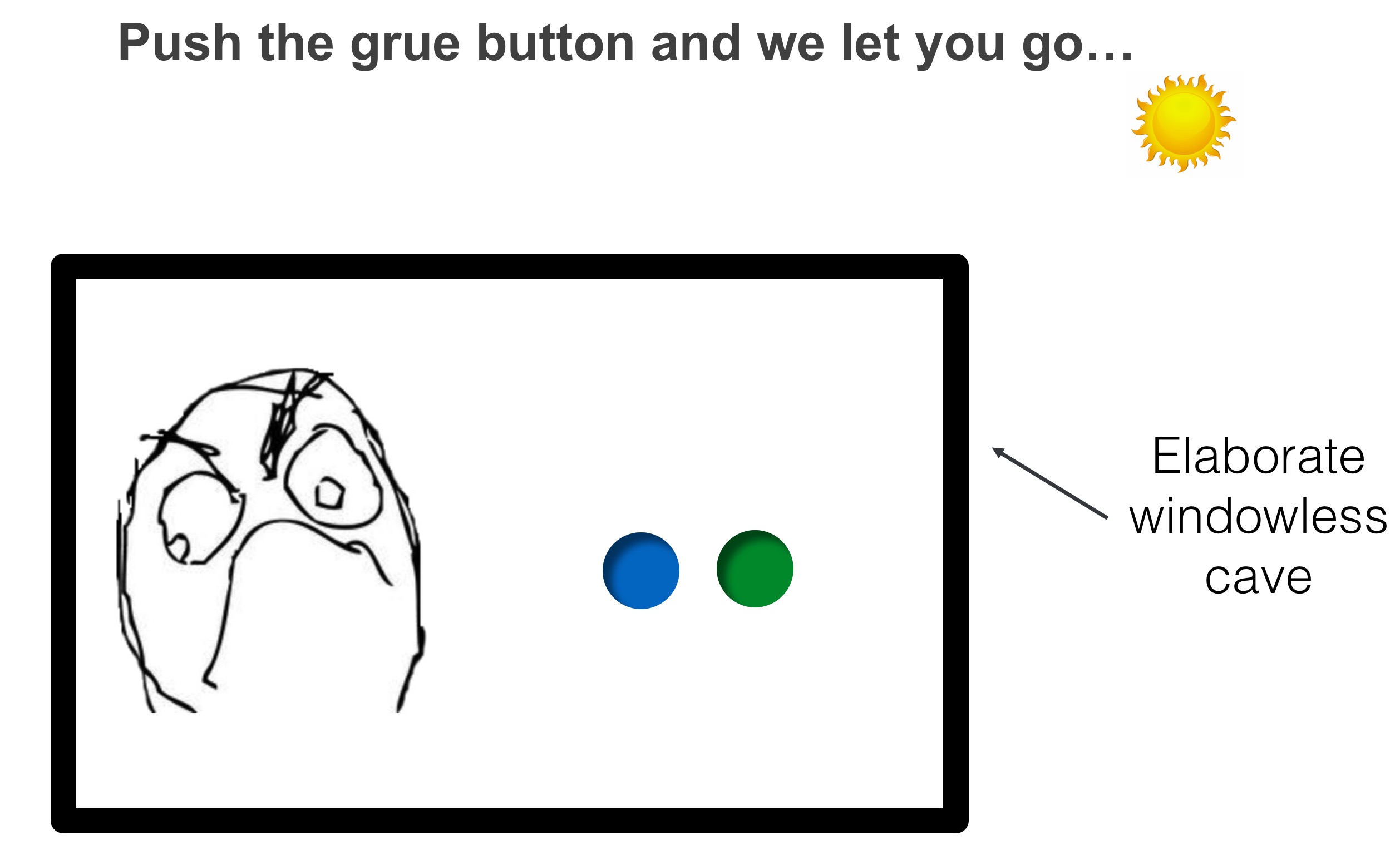
We say that grue-ness and time of day exhibit “informational synergy” with respect to predicting the visual appearance of an object. Synergy means the “whole is more than the sum of the parts” and in this case, knowing either the time of day or the grue-ness of an object does not help you predict its appearance, but knowing both together gives you perfect information.
Grues in deep learning
This whimsical story is a very close analogy for what happens in the field of “representation learning”. Neural nets and the like learn representations of some data consisting of “neurons” that we can think of as concepts or words in a language, like “grue”. There’s no reason for generic deep learners to prefer a representation involving grue/bleen to one with blue/green because either will have the same ability to make good predictions. And so most learned representations are synergistic and when we look at individual neurons in these representations they have no apparent meaning.
The importance of interpretable models is becoming acutely apparent in biomedical fields where blackbox predictions can be actively dangerous. We would like to quantify and minimize synergies in representation learning to encourage more interpretable and robust representations. Early attempts to do this are described in this paper about synergy and another paper demonstrates some benefits of a less synergistic factor model.
Revenge of the Grue
Now, after making this case, I want to expose our linguo-centrism and provide the Grue apologist’s argument, adapted from a conversation with Jimmy Foulds. It turns out the Grue speakers live on an island that has two species of jellyfish: a bleen-colored one that is deadly poisonous and a grue-colored one which is delicious. Since the Grue people encounter these jellyfish on a daily basis and their very lives are at stake, they find it very convenient to speak of “grue” jellyfish, since in the time it takes them to warn about a “blue during the day but green at night jellyfish”, someone could already be dead. This story doesn’t contradict the previous one but highlights an important point. Synergy only makes sense with respect to a certain set of predicted variables. If we minimize synergies in our mental model of the world, then our most common observations and tasks will determine what constitutes a parsimonious representation of our reality.
Acknowledgments
I want to thank some of the PhD students who have been integral to this work. Rob Brekelmans did many nice experiments for the synergy paper. He has provided code for the character disentangling benchmark task in the paper. Dave Kale suggested key aspects of this setup. Finally Hrayr Harutyunyan has been doing some amazing work in understanding and improving on different aspects of these models. The code for the disentangled linear factor models is here, I hope to do some in depth posts about different aspects of that model (like blessings of dimensionality!).
Filed under: Posted by Greg Ver Steeg | 2 Comments

The grue parable is a great thought experiment. I do have a slight nitpick — introducing the extra variable ‘poisonous’ to the problem turns it into one of reinforcement/value, which muddies the waters somewhat. The key issue is identity: on the Grue island, a grue jellyfish maintains its identity through time, whereas a green one does not. That’s what really distinguishes Grue island from the rest of our world. Compare this to the checkerboard illusion (http://www.illusions.org/dp/1-67.htm): according to human visual perception, the absolute greyscale of the lone square doesn’t identify the square, it is only the relative greyscale that matters, because objects maintain identity under spatiotemporal fluctuations in illumination.
The trouble with machine learning up to this point has been the lack of an objective quantification of what it means to successfully disentangle the ‘ground truth’ features of the world. Evaluation of success still ultimately boils down to human judgement – hence the panels of example images in VAE/GAN papers. What you’re proposing is (in my view) a candidate for the *definition* of a feature/structure of the world. This is revolutionary. It has the potential to replace all the prior information that is baked into present NN-based learning (eg, CNNs for vision) with a way to extract structure directly from unsupervised data — it’s a recipe for AGI.
I’m not 100% sold on the approach of using TC(x;y) as the measure of synergy. As Judea Pearl notes (http://ftp.cs.ucla.edu/pub/stat_ser/r414.pdf), conditioning on an explanatory variable doesn’t always reduce correlations between other variables: it can also increase them. Seems to me that the correct approach is to use the Berschinger/Schneidmann/Ay/… measure of synergy. That is, take the entropy difference between the maximally-dependent P(x_1,x_2,…) vs the version that maximizes entropy subject to consistency with the set of marginals {P(x_1,y),P(x_2,y)…}. This synergy quantifier closes the ‘informational backdoor’ so that Simpson’s paradox can’t arise.